
Every week we feature a new startup at Fundsup that forces a radical breakthrough. This time we chat with Simon Brouwer, Co-founder & CTO of Syntho.
Who is Syntho?
We are three friends who know each other from the university in Groningen. Since we’ve always been engaged in data-driven innovation, privacy was something that presented challenges for us all. We founded Syntho with the ambition to provide trust in data-driven innovation. Our mission is to enable an open data economy, where we can freely use and share data, but where we also preserve the privacy of people.
Can you tell a bit about your backgrounds?
Marijn (left) has a background in computing science, industrial engineering and finance and has been working as a consultant in fields of cybersecurity and data analytics. Simon (middle) has an education in artificial intelligence and has experience as a data scientist in a wide variety of companies. Wim Kees (right) has a background in economics, finance and investments and has experience in (software) product development & strategy.
And what exactly are you doing?
Syntho enables organizations to boost data-driven innovation in a privacy-preserving manner. We provide AI-software for generating synthetic data, as an alternative to using real personal data.
Synthetic data, what is it?
Organizations can use our software to generate an entirely new set of fresh data records. Information to identify real individuals is simply not present in a synthetic dataset. What makes us unique is that we apply machine learning. This means our solution is able to preserve the structure and properties of the original dataset. In accordance, one experiences similar data quality with the synthetic data as with the original dataset.
Synthetic data by Syntho can be used for any data analysis as though it is real data. Outcomes of data analysis on synthetic data will be nearly identical to analysis results on the original data. Our customers use synthetic data to boost innovation, improve insights and even train AI models.
What is the impact of your business?
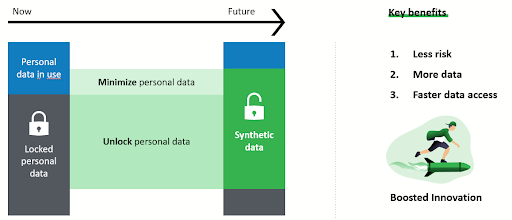
Why use real data when you can use synthetic data? We often ask this question to organizations that have the ambition to become more data-driven. Synthetic data improves the way organizations work with data in two ways:
1. Organizations can minimize personal data and thereby reduce data breaches for example.
2. Organizations can unlock personal data that was formerly locked due to privacy restrictions.
These opportunities enable organizations to build a strong foundation for data-driven innovation by reducing the risks of using personal data, increasing the amount of data available, and making data more readily accessible.
Where do you see its main application?
Although privacy challenges are present across sectors and organizations that work with personal data, our “go to market strategy” focuses on specific use cases. The key use cases we focus on include:
1. Data sharing: privacy-preserving public and third-party data sharing by sharing synthetic data as an alternative for sharing original data.
2. Data retention: overcome legal retention periods and eliminate storage risks by building a track record with synthetic data as an alternative for storing original data.
3. Agile analytics: eliminate time-consuming governance blocking data access and innovation by having synthetic datasets or a synthetic data warehouse.
4. Data augmentation: intelligent synthetic data sampling to reduce bias and balanced datasets.
5. Data commerce: responsibly monetize your data assets in synthetic form.
6. Testing & development: prevent production data in your test & development environment.
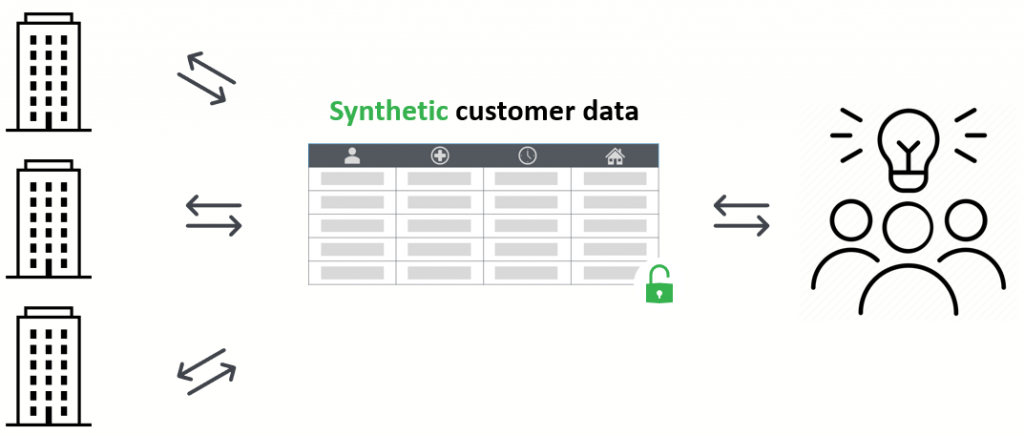
Could you illustrate how this would work in practice?
Sure. Let me illustrate the data sharing use case. Companies typically collect sensitive customer data they are not allowed to share with third parties due to privacy reasons. Consequently, these companies are limited in realizing data-driven collaboration. Our solution: share this data in synthetic form to alleviate any privacy risks while preserving the value of the original data. The collaborating parties can test, develop and innovate using the synthetic data.
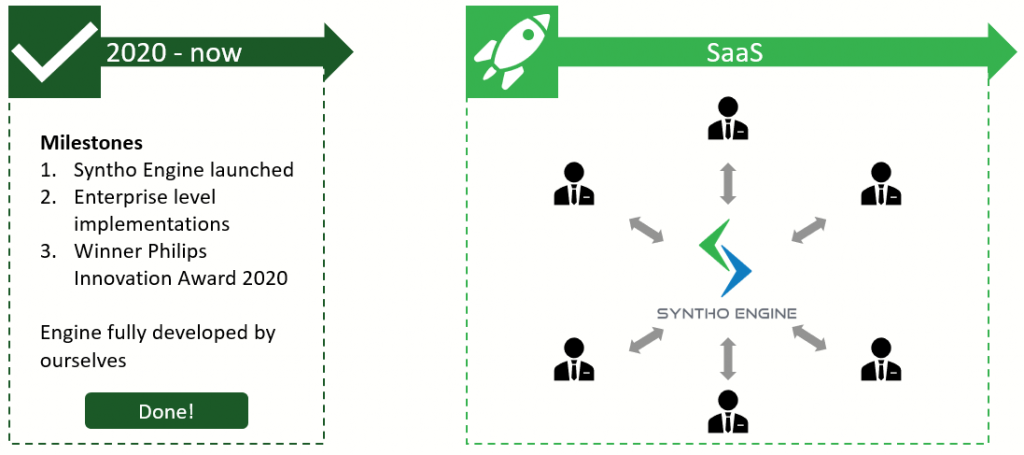
Where do you stand right now and what are your next steps?
Currently, we are bootstrapped and have already realized various important milestones. We launched our Syntho Engine, realized various successful (enterprise-level) implementations, finished an incubator program, and recently won the Philips Innovation Award 2020. Our next step is to transform the current version of our Syntho Engine towards a SaaS solution so that everyone can benefit from synthetic data anywhere, anytime.
What kind of investors are you looking for and what would be the ideal investor match?
As mentioned, we are bootstrapped and developed everything ourselves. Now, we want to raise funding in order to realize our next step: transform towards a highly-scalable SaaS solution. Our ideal investor is characterized by having added value in addition to ‘being an investor’. We are looking for someone who could help us in realizing our growth ambition towards a SaaS solution, recognizes data privacy challenges, and has the ambition to become closely involved. Advanced knowledge on the following topics would be highly valuable: strong network, SaaS experience, and a portfolio containing other SaaS organizations. Above all, we are looking for energy, vibe, and ambition.
Best of luck with everything!
Thanks, check out our pitch deck on Fundsup: https://api.fundsup.co/go/P0Jvyt0Yh